
有一个项目,mysql 语句采用了not in,结果某些页面打开需要40多秒,排查sql语句后,发现是采用了 not in 语法导致全表扫描,消耗了大量的时间,飘易记录下优化的过程:
项目简介:
会议应该签到表 signshould :15万条数据
会议实际签到表 sign :10万条数据
请假表 leaves :1000条数据
其中字段:mid:会议id,uid:用户id
【例一】:原先的 not in 语句:
select uid from signshould where mid=897 and uid not in(select uid from sign where mid=897 and thetype=0) and uid not in(select uid from leaves where mid=897)
时间: 18.898s
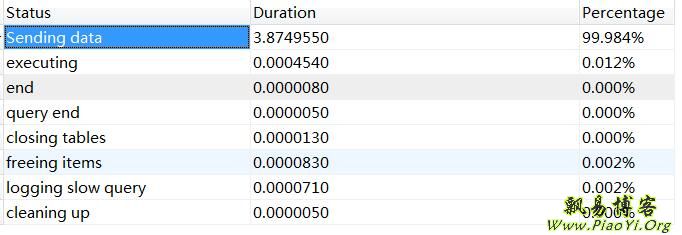
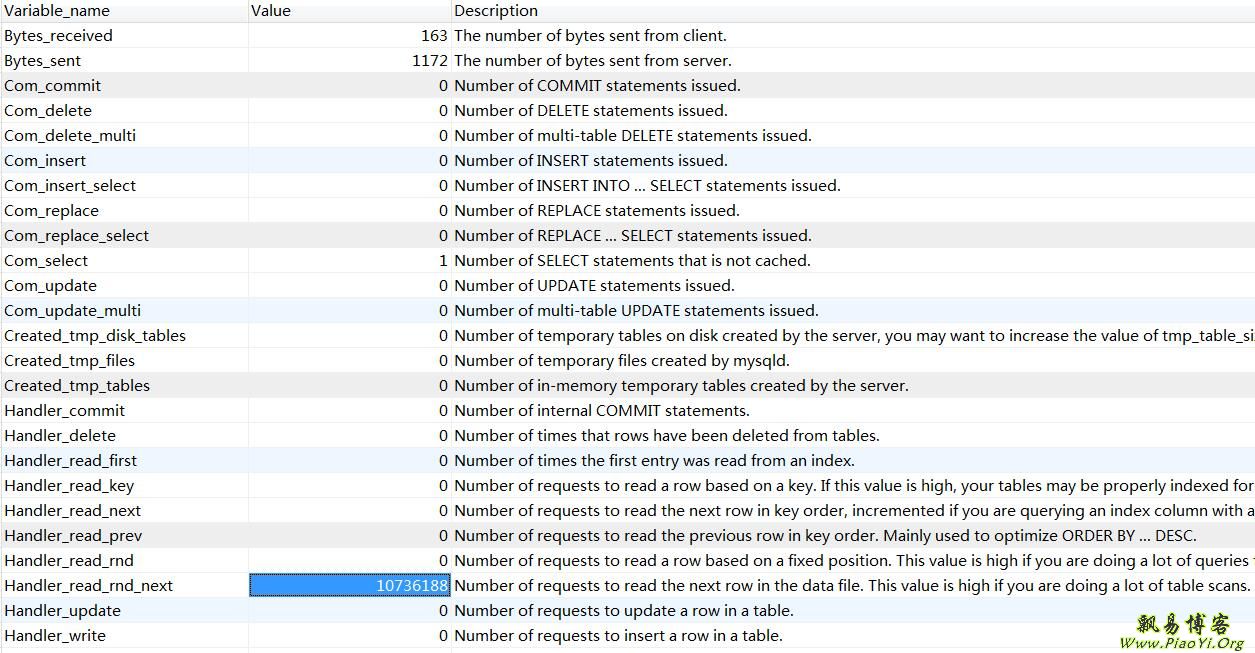
查看状态,可以看到 Handler_read_rnd_next 值很大,达到了 1073万次请求,该参数的含义:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
说明上诉sql语句引起了全表扫描。
explain SQL语句:
 此时,我们在 mid 和 uid 上并未建立索引。
此时,我们在 mid 和 uid 上并未建立索引。
优化思路1:在 mid 和 uid 上建立索引后再 explain:

时间下降到: 0.039s。
优化思路2:采用left join 和 右表.id is null 的方法优化:
select a.* from signshould as a LEFT JOIN (select * from sign where mid=897 and thetype=0) as b ON a.uid=b.uid LEFT JOIN (select * from leaves where mid=897) as c ON a.uid=c.uid where a.mid=897 and b.uid is null and c.uid is null
没有建立索引时间: 0.031s
建立索引时间: 0.016s
飘易发现采用 left join 方法执行sql语句的时候:
没有索引的前提下,执行时间仅为not in方法的 1.6/千分 【0.031/18.898】;
建立了索引后消耗时间仅为not in(也建立索引)方法的 40% 【0.016/0.039】。
| 索引 | not in 执行时间 | left join 执行时间 | 优化后时间占比 |
| 无索引 | 18.898 | 0.031 | 1.6‰ |
| 有索引 | 0.039 | 0.016 | 40% |
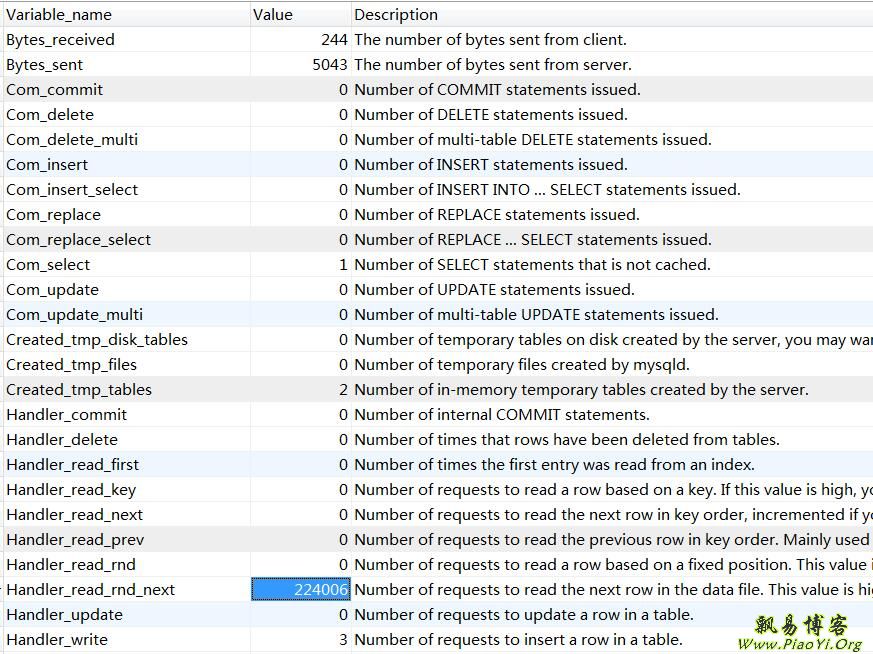 可以看到优化后的 Handler_read_rnd_next 值下降到了22万。
可以看到优化后的 Handler_read_rnd_next 值下降到了22万。
注:LEFT JOIN 关键字会从左表那里返回所有的行,即使在右表中没有匹配的行。
EXPLAIN sql:

【例二】:原先的not in的sql语句2:
select uid from sign where mid=674 and thetype=0 and uid not in(select uid from sign where mid=674 and thetype=1) and uid not in(select uid from leaves where mid=674)
时间: 39.208s
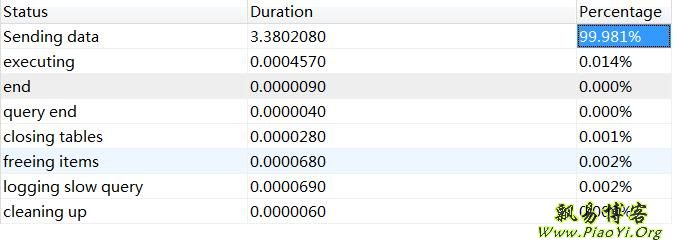
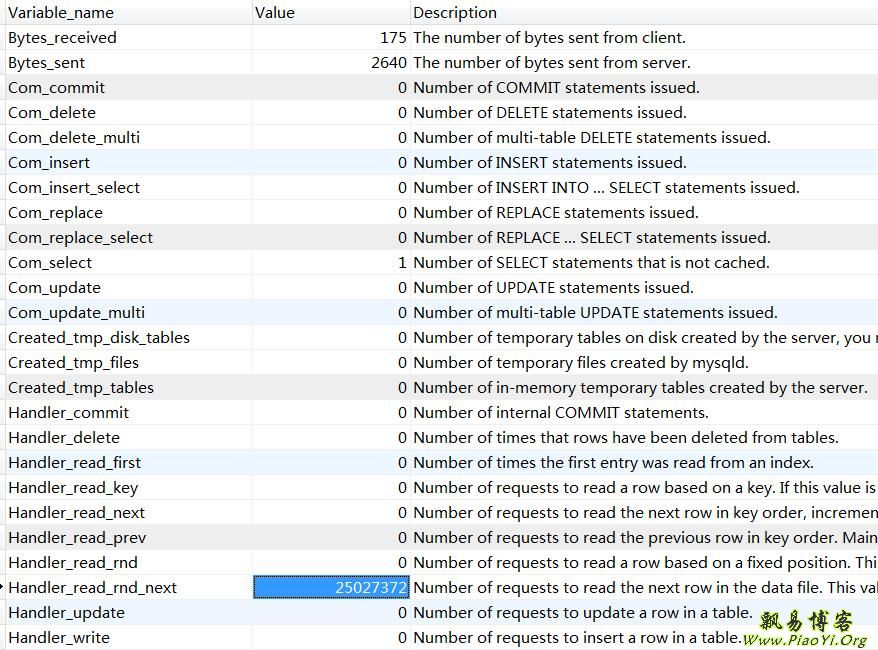 可以看到 Handler_read_rnd_next 值很大,达到了 2500万,也是全表扫描导致的。
可以看到 Handler_read_rnd_next 值很大,达到了 2500万,也是全表扫描导致的。
采用left join 和 右表.id is null 方法优化:
select a.* from sign as a LEFT JOIN (select * from sign where mid=674 and thetype=1) as b ON a.uid=b.uid LEFT JOIN (select * from leaves where mid=674) as c ON a.uid=c.uid where a.mid=674 and a.thetype=0 and b.uid is null and c.uid is null
时间: 0.048s
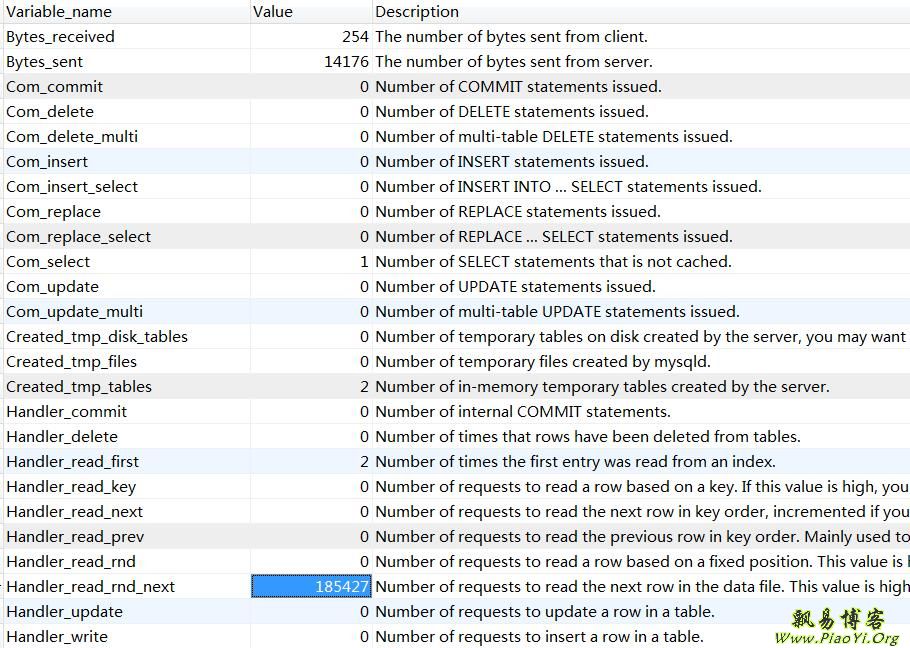 优化后 Handler_read_rnd_next 的值下降到了 18万。
优化后 Handler_read_rnd_next 的值下降到了 18万。
LEFT JOIN 要点:
select t1.id,t2.id from t1 left join t2 on t1.id = t2.id and t1.id>1 and t2.id<>3
在mysql的 left join 中条件放在on后面和在where后面是不同的;
1. on后面只针对于t2表进行过滤,所以上面的 t1.id>1 将不起作用,切记,切记;
2. where后面会对最终结果产生影响,所以如果t2.id<>3放到on后面和where后面也是会返回不同的结果;
例如下面脚本一会比脚本二多返回一些数据。
select * from test2 left join test1 on test2.id = test1.id and test1.id<>3 where test2.id <>6; -- select * from test2 left join test1 on test2.id = test1.id where test2.id <>6 and test1.id<>3;
本文完。